この記事は、文字入出力 からの続編です。
この記事は、絵でわかる プログラムとは何か(5)~データ~ の一記事です。
この記事のポイント
- ディスプレイへの画像出力は、以下の3ステップ。
- 画像データとその表示位置情報をグラフィックス処理回路へ送る
- グラフィックス処理回路でレンダリング(画像合成したフレームデータ作成)を行う
- フレームデータを連続して、グラフィックス処理回路からディスプレイに送る
- 画像データには、ラスタデータとベクタデータがある。
- ベクタデータは、ラスタデータよりズームアップに強いが、複雑な色構造に弱い。
- ベクタデータも、レンダリングでラスタデータ化(ラスタライズ)される。
- 音声データは、ADコンバーターでデジタル化し、再生時にDAコンバーターでアナログ化する。
- 動画データは、多数の静止画データと長時間の音声データの集まりなので、コンテナファイルとして保存される。
- 動画データは、そのままだと非常にデータ量が多くなるため、通常は圧縮して保存される。
- コンテナファイル用に、データ圧縮・解凍を行うプログラムをコーデックと言う。
画像(image)
画像出力
前記事(文字入出力)では、画面上に”A”の文字を出力する際の、OSでの処理の流れを示しました。
0. あらかじめ、各グリフ用の画像データ(フォントデータ)をメモリにロードしておく。
- 文字コード 01000001 と、その文字を表示するべき位置(カーソル位置等)の情報を受け取る。
- 文字コード 01000001 に対応するグリフ “A” のフォントデータと、その表示位置情報をグラフィックス処理回路へ送る。
- グラフィックス処理回路で、このグリフ “A” のフォントデータを、基になるフレームデータ内のあるべき位置に合成し、ディスプレイに送るフレームデータを完成させる。(レンダリング)
- 完成したフレームデータの前後をつなぎ、連続した映像データとしてディスプレイに送る。
ここでは、1. で画像(フォント)データがすでに用意されており、2. 以降は、指定された画像データをディスプレイに出力するまでの処理を示しているだけでした。
したがって、文字に限らずディスプレイへ出力する画像はすべて同じ手順、つまり以下の3ステップで処理されます。
- 画像データとその表示位置情報をグラフィックス処理回路へ送る
- グラフィックス処理回路でレンダリング(画像合成したフレームデータ作成)を行う
- フレームデータを連続して、グラフィックス処理回路からディスプレイに送る
画像データ
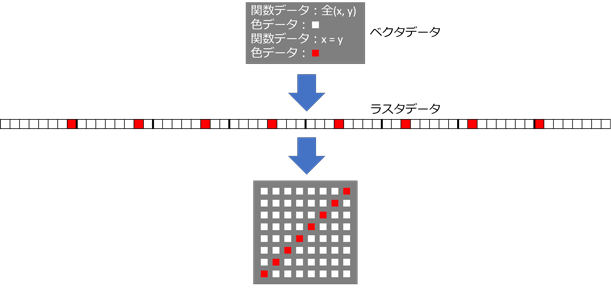
では、画像データはどういうものかというと、画像データには、ラスタ(raster)データとベクタ(vector)データの2種類があります。
ラスタデータ
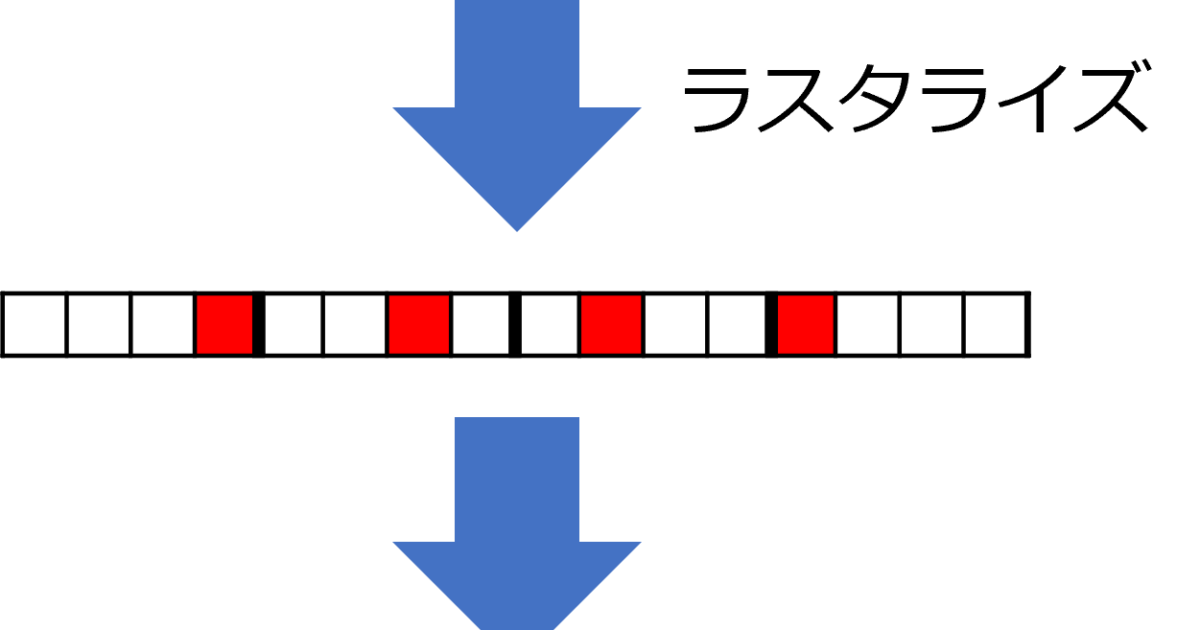
ラスタ(raster)は、熊手の掻き跡のことで、走査線像を意味します。したがって、ラスタデータは、ピクセルごとの色データをあらかじめ走査順に合わせて記録してあるビットマップのようなデータになります。
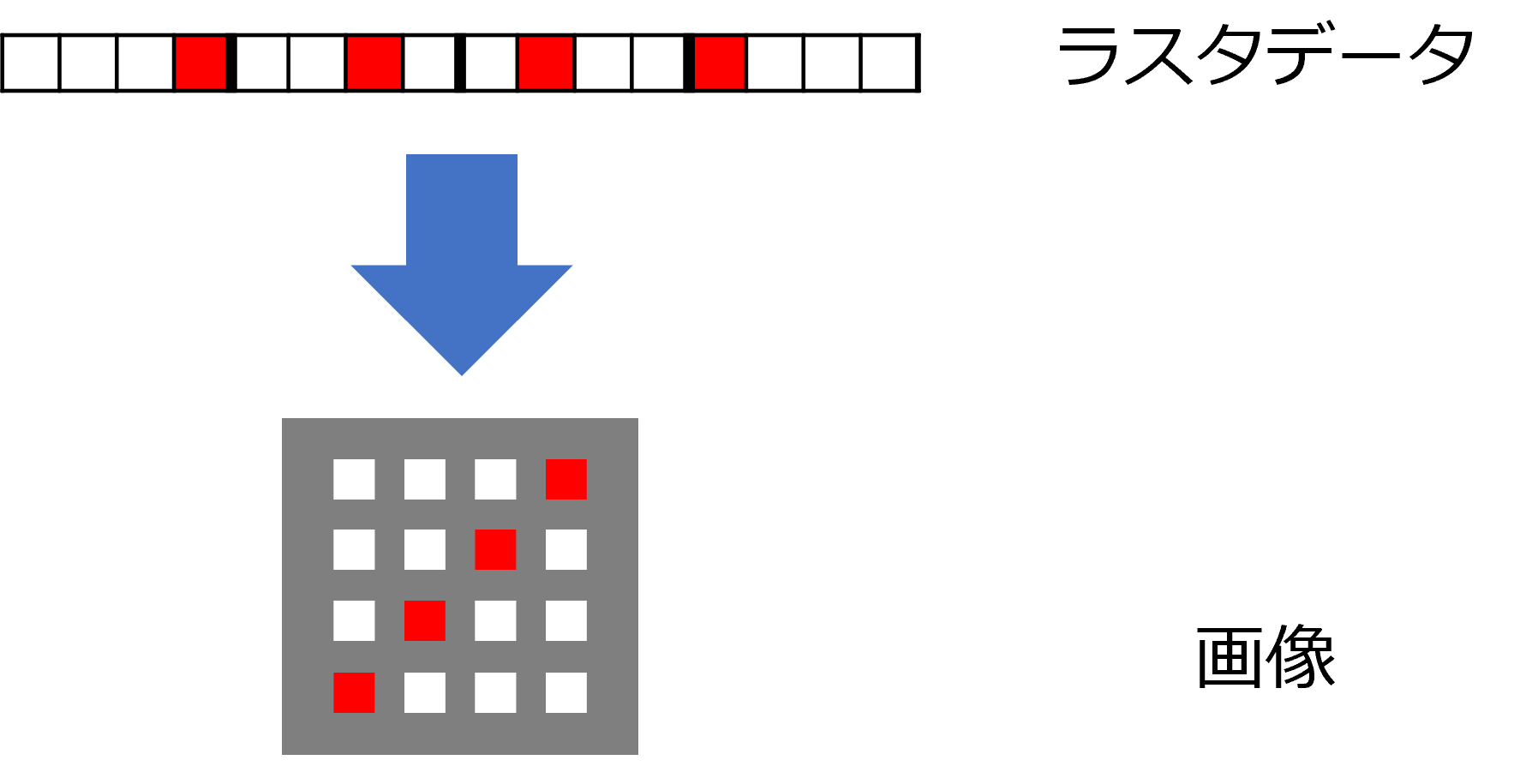
デジタルカメラやスキャナによる記録も、その場でラスタデータが作られます。色データの例としては、以下のようなものがあります。
- RGB
- 光の3原色=赤(Red)・緑(Green)・青(Blue)それぞれの度合いを数値で表したデータ
- CMYK
- 印刷用インクの4原色=シアン(Cyan)・マゼンタ(Magenta)・イエロー(Yellow)・ブラック(blacK)それぞれの度合いを数値で表したデータ
- HSL
- 色の3要素=色相(Hue)・彩度(Saturation)・明度(Lightness)それぞれの度合いを数値で表したデータ
なお、それほど色構造が複雑でない画像には、圧縮変換を施すことで、データ量を少なくすることができます。
ベクタデータ
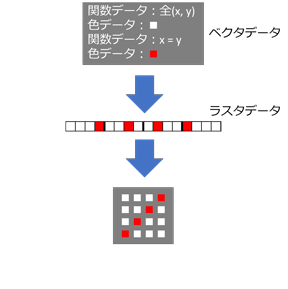
ベクタ(vector)とはベクトル、つまり向きと長さを持った線のことです。直線や曲線、面などの図形は関数で表現でき、関数はベクトル(描線)の集まりとして表現できます。ベクタデータは、数学的な関数グラフの座標に相当する各ピクセルへの描線(色データの割り当て)データを、順次記録したデータです。
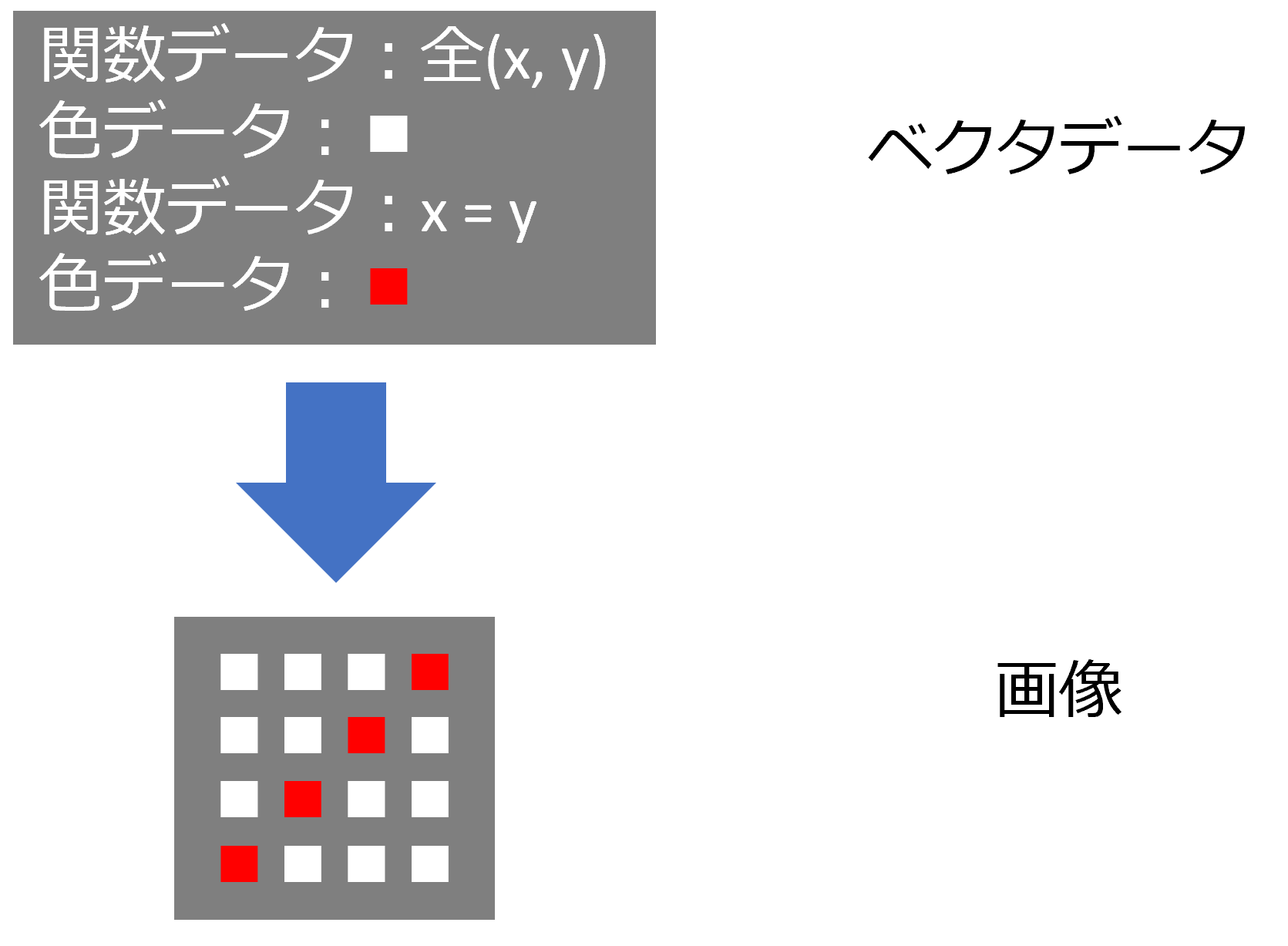
ラスタデータとベクタデータの比較
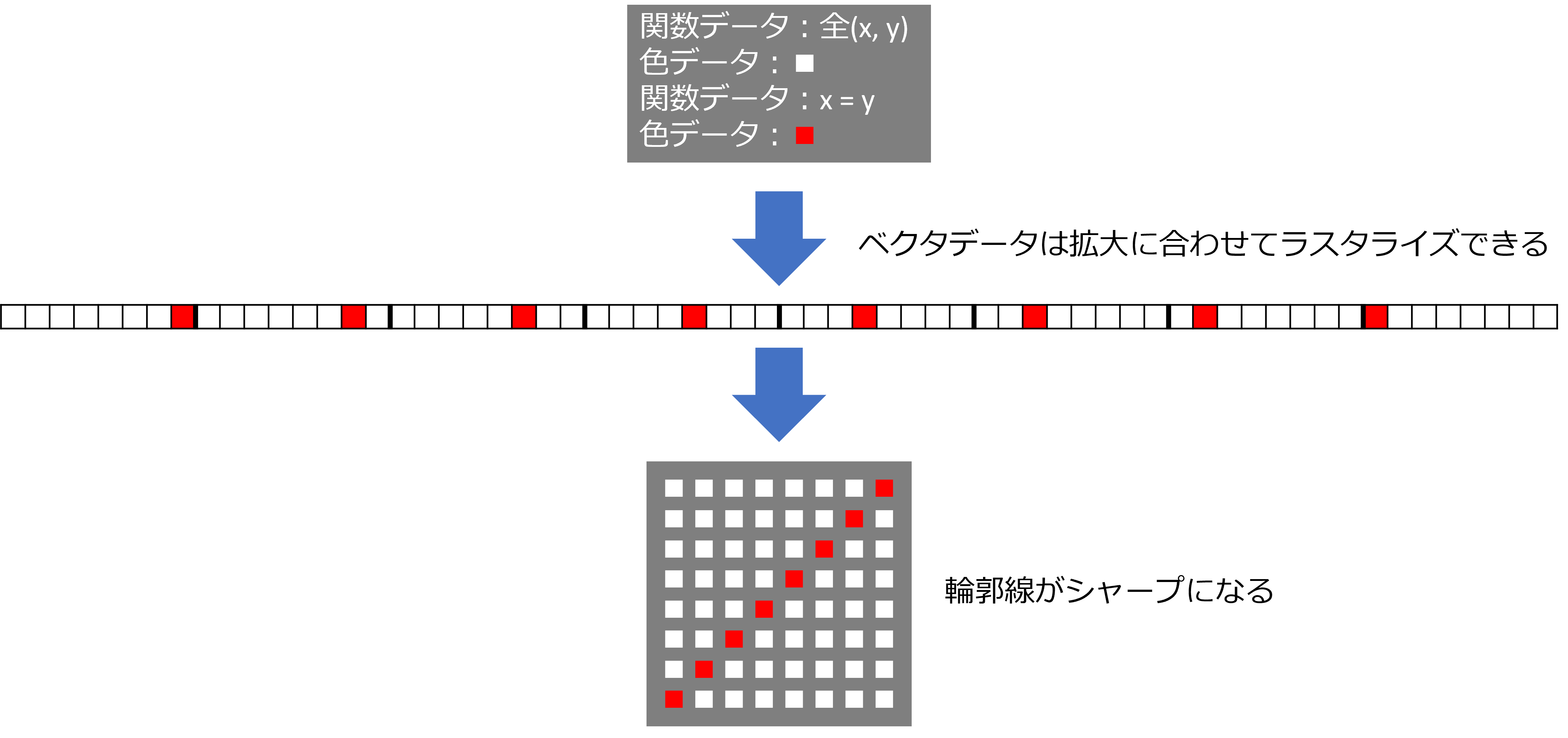
ベクタデータは、ラスタデータのようなピクセルごとのデータを持たず、関数データと、それに沿った色データだけを持ちます。しかし、ベクタデータも、レンダリング段階では関数計算により、色データが各ピクセルに割り当てられたラスタデータに変換されます。(この変換処理をラスタライズと言います。)
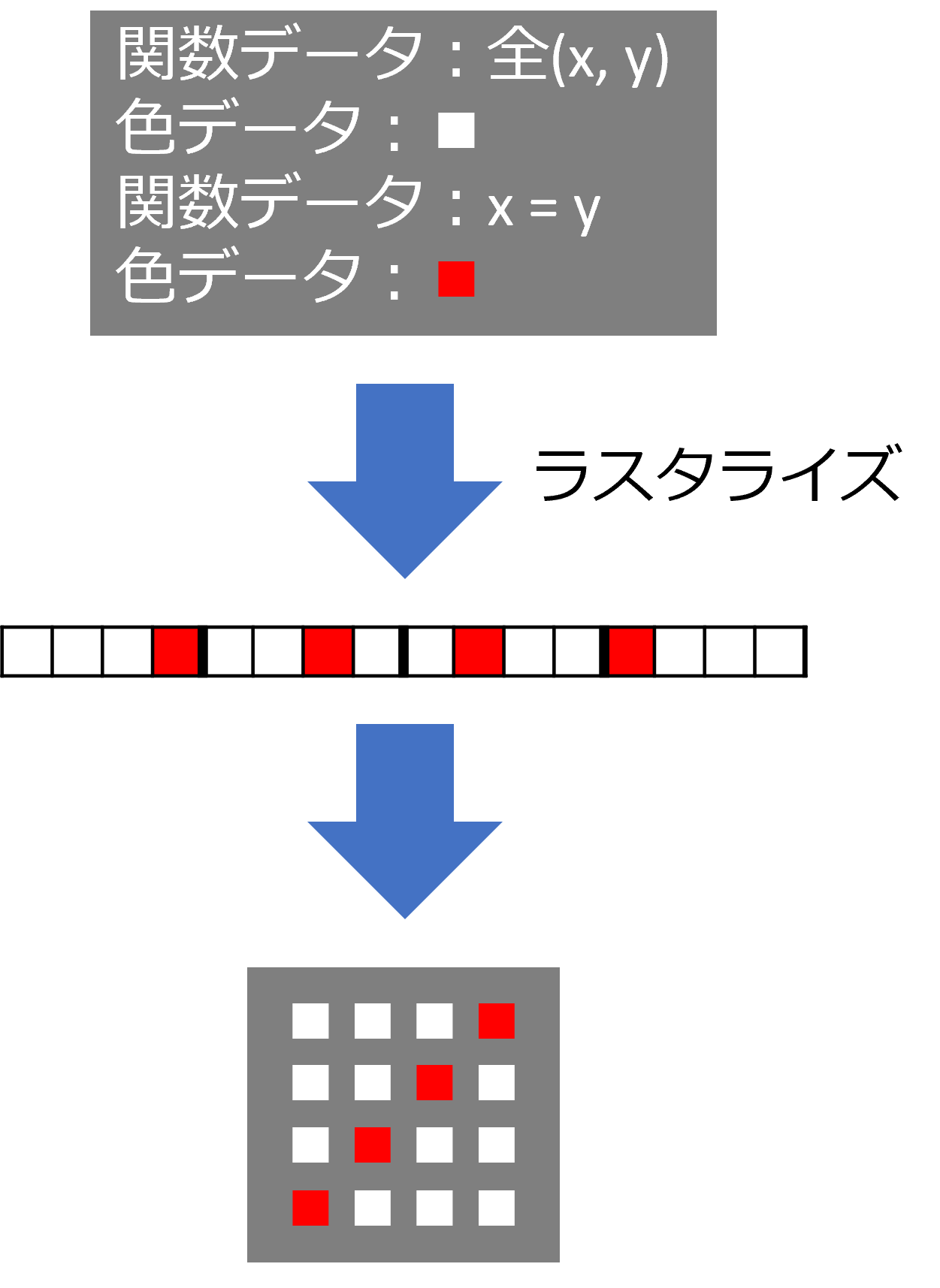
このため、ベクタデータは画像サイズを拡大(ピクセル数を増殖)しても、同じ関数の再計算によってあるべき線が引け、ラスタデータよりも、あるべき画像をよりシャープに再現できます。
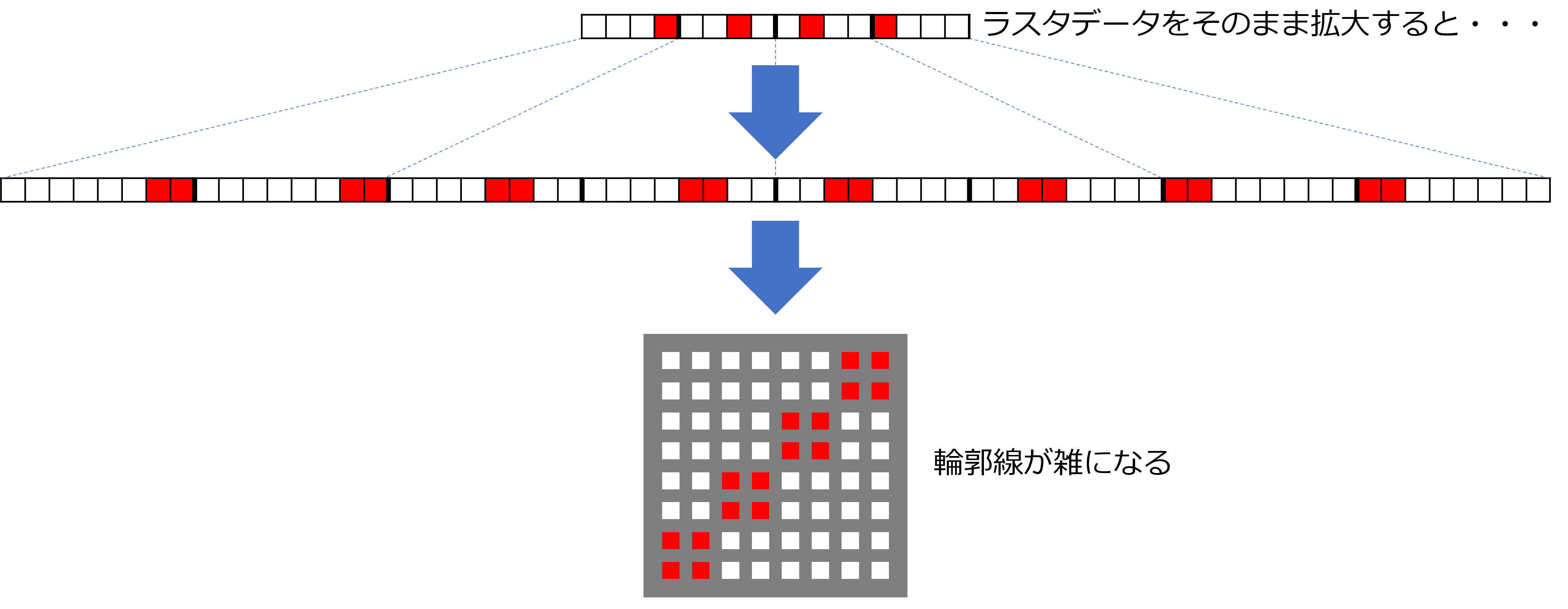
一方、複雑な色構造を持つ画像をベクタデータで表現しようとすると、必要な関数の種類が膨大になり、並行処理できない計算が多くなります。このため、グラフィックス処理回路の性能を上回るフレーム変化が起こるとそれについていけず、ディスプレイ画面上の映像に遅延や欠落などが生じます。
音声(audio)
スピーカーとマイクのしくみ
音声は、ディスプレイを使わずに、スピーカーを通して出力されます。スピーカーは、スピーカーの中心にあるコイルを電磁力で振動させ、音(空気振動)を発生します。マイクからの入力データも電磁力の振動です。

アナログデータとデジタルデータ
よって、その電磁力の振動変化を記録したものが音声データになります。しかし、マイクやスピーカーが扱えるのはアナログの音声データだけです。一方、コンピューターが扱えるのはデジタルデータだけです。
そこで、コンピューターでの音声データの利用にはデジタルデータとアナログデータを変換するコンバーター(converter)が使われます。
convert は「変換する」という意味の英語です。
アナログデータからデジタルデータへ変換するコンバーターをADコンバーター(Analog to Digital Converter)と言い、デジタルデータからアナログデータへ変換するコンバーターをDAコンバーター(Digital to Analog Converter)と言います。
ADコンバーターやDAコンバーターは、音声だけでなく、様々なデジタル⇔アナログ変換に使われます。

動画(video)
動画データは、基本的には画像データ(静止画)を連続させたフレームデータです。(監視カメラ映像のイメージ)
コンテナファイル
しかし、映画やテレビの影響もあり、フレームデータに音声データや字幕データなども同期して再生できることが望まれます。よって、動画データは単独で扱われることよりも、これらの別種データと共にひとまとめにしたパッケージデータで扱われることが多くなっています。このパッケージデータを記録したファイルのことをコンテナファイルと言います。
データ圧縮(compression)
画像データに、より細部まできれいな高画質を記録しようとすると、ピクセル数を増やす必要があり、データ量が膨大になります。
音声データも、より微細な振動変化をとらえた高音質を記録しようとすると、時間当たりのデータ量が膨大になります。
そこで、高画質・高音質をより小さなデータ量で記録するための工夫として、データ圧縮という技術が使われます。情報量を変えずに、データ量だけ小さくなるように変換しているので、「圧縮」という言葉が使われます。
データ圧縮には、
- データ中にある、より頻繁・不変な部分の記録データ量を極小化した、元に戻せる可逆圧縮
- 人間にとって、より不変的と感じられる部分を「不変」とした、元に戻せない非可逆圧縮
の2種類があります。
「不変」ということは「変化情報」が不要ということで、再現のために必要な情報量(データ量)は小さくなります。
逆に変化が頻繁にあるということは、それだけ多くの「変化情報」が再現のために必要となり、情報量(データ量)が大きくなります。
「不変」には、空間的不変と時間的不変が考えられますが、どちらもデータとしては、一定のパターンの繰り返し(関数)になります。
<可逆圧縮の例>
- エントロピー符号化(略語化)
- より頻出する情報(低エントロピー)に短いビット数を割り当て、よりレアな情報(高エントロピー)に長いビット数を割り当てる。
例: 1月1日月曜日および1月2日火曜日 [408ビット] ⇒ 1/1(月), 2(火) [128ビット] - ランレングス符号化(掛け算化)
- 不変部分のデータを、不変部分の最初の情報 × 不変部分(run)の長さ(length) を表すデータに置き換える。
例: すもももももももものうち [288ビット] ⇒ すも×8のうち [144ビット]
<非可逆圧縮の例>
- 一定範囲内の微妙な色の違いを同色扱いにする。
- 一定の条件下で人の耳にほとんど聞こえない音成分を無音にする。
- 動画中の各フレームにおいて、その前後フレームから予測できるピクセルデータを抜き、予測との差分ピクセルだけをフレームデータにする。
非可逆圧縮は、人間にとっての情報量は変わりませんが、真の情報量(コンピューターが扱えるデータ量)は削減されているため、元に戻せなくなります。情報量が減るため、非可逆圧縮は人間以外にとって圧縮とは言えません。
データ圧縮は、全てのデータを同じように圧縮できるわけではなく、対象データの特徴(どういう不変部分がどれだけ頻出するか)によって、利用すべき圧縮技術が異なります。
例えば、数本の斜め線のように構成が単純なラスタデータをベクタデータに変換することは、良好な可逆圧縮になります。
コーデック
このように、データを圧縮すると、そのままでは再生(人間向けの出力)ができないデータ形式になります。
そのままで再生できるデータ形式とは、例えば画像であればそのままグラフィックス処理回路へ出力できるラスタデータ形式、音声であればそのままDAコンバーターを通して音声信号として出力できるWAVE形式であり、それ以外の圧縮されたデータ形式は、そのままでは再生できないデータ形式になります。
このため、再生の際には圧縮されたデータの解凍(そのまま再生ができるデータ形式に逆変換すること)が必要になります。
この圧縮と解凍のデータ形式変換のセットをコーデック(codec)と言います。
非可逆圧縮では情報量が減っているため、元データへの完全な逆変換はできませんが、データ形式としては元データと同じデータ形式に戻します。
この記事のまとめ
ディスプレイへの画像出力は、グラフィックス処理回路でレンダリングしたフレームデータを連続してディスプレイに送ることです。
画像データには、ラスタデータとベクタデータがあり、ベクタデータは、ラスタデータよりズームアップに強いが、複雑な色構造に弱い特徴があります。ただし、ベクタデータも、レンダリング段階ではラスタデータ化(ラスタライズ)されます。
音声データは、アナログ音源からも、ADコンバーターでデジタル化できます。再生時には、DAコンバーターでアナログ化して再生します。
動画データは、多数の静止画データと長時間の音声データの集まりなので、コンテナファイルとして保存されます。動画データは、そのままだと非常にデータ量が多くなるため、通常は圧縮して保存されます。
コンテナファイル用に、データ圧縮・解凍を行うプログラムをコーデックと言います。
次は、データ型 に進みましょう。
この記事は、絵でわかる プログラムとは何か(5)~データ~ の一記事です。
コンピューターのしくみ全体を理解したい場合は、以下の2コースがお勧めです。
日本全国 オンラインレッスン にも対応しています。
知りたいことだけ単発で聞きたい場合は、 オンラインサポート をご利用ください。