この記事は、映像・音声 からの続編です。
この記事は、絵でわかる プログラムとは何か(5)~データ~ の一記事です。
この記事のポイント
- コンピューター内で扱われる全てのデータはバイナリデータ。
- 負数のバイナリデータ化には、通常、「2の補数」が使われる。
- 小数のバイナリデータ化には、通常、「浮動小数点法」が使われる。
- バイナリデータ化前のデータのタイプを、データ型(data type)と言う。
- 特に、ブール型1ビットのバイナリデータをフラグ(flag)と言う。
- 通常、画像型や音声型のような非テキストデータ型はなく、FILE型にまとめられる。
- データ構造を持つテキストデータは、適切なファイルフォーマットに合わせて扱う。
プログラム内で扱われるデータ
全てのデータはバイナリデータに変換
この章の冒頭で、コンピューターは基本的に電気のON/OFFパターン(2進数の数値)しか扱えないということを書きました。
確かに、文字列や画像、音声、動画など、様々な数値以外のデータまで、コンピューターで扱えているように見えます。しかし、それらはコンピューター外での見え方です。実際は、これまで見てきたように、コンピューター内では数値に変換されたデータが扱われているのです。
この変換後の、電気のON/OFFパターンだけで表せる2進数の数値を、バイナリデータ(binary data)と言います。マシンコードのデータは、全てバイナリデータである必要があります。
特殊な数値もバイナリデータに変換
また、数値と言っても、ON/OFFパターンだけでは負号(マイナス)や小数点が使えません。
このため、負整数や小数のデータも、負号(マイナス)無し・小数点無しの数値(バイナリデータ)に変換して、処理します。
負整数から変換する例
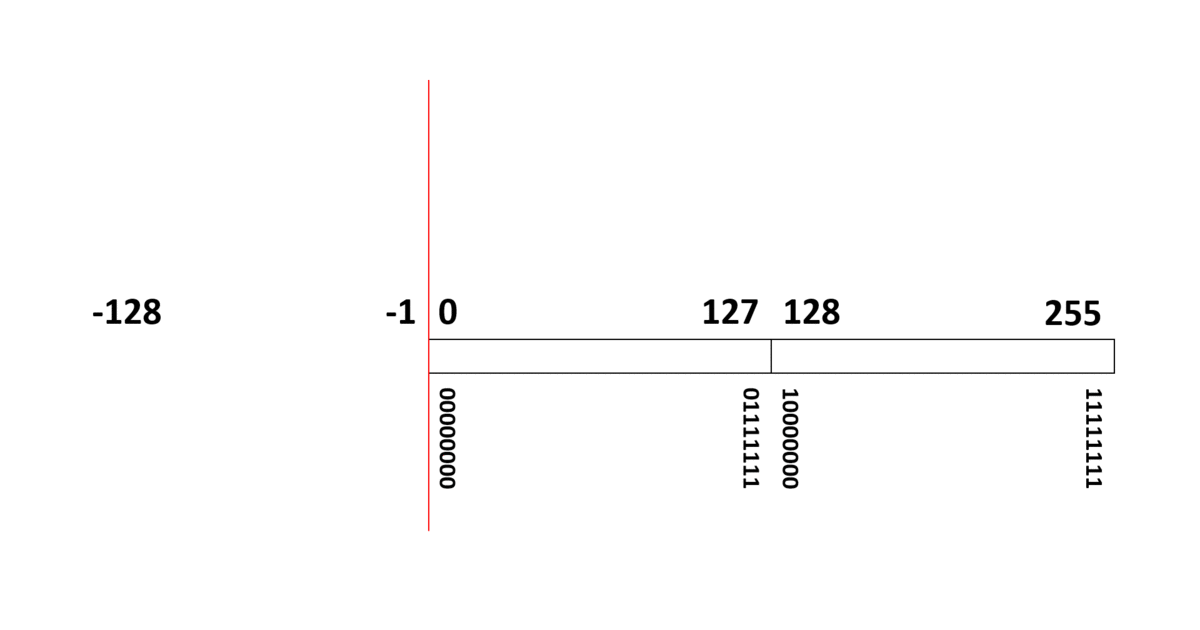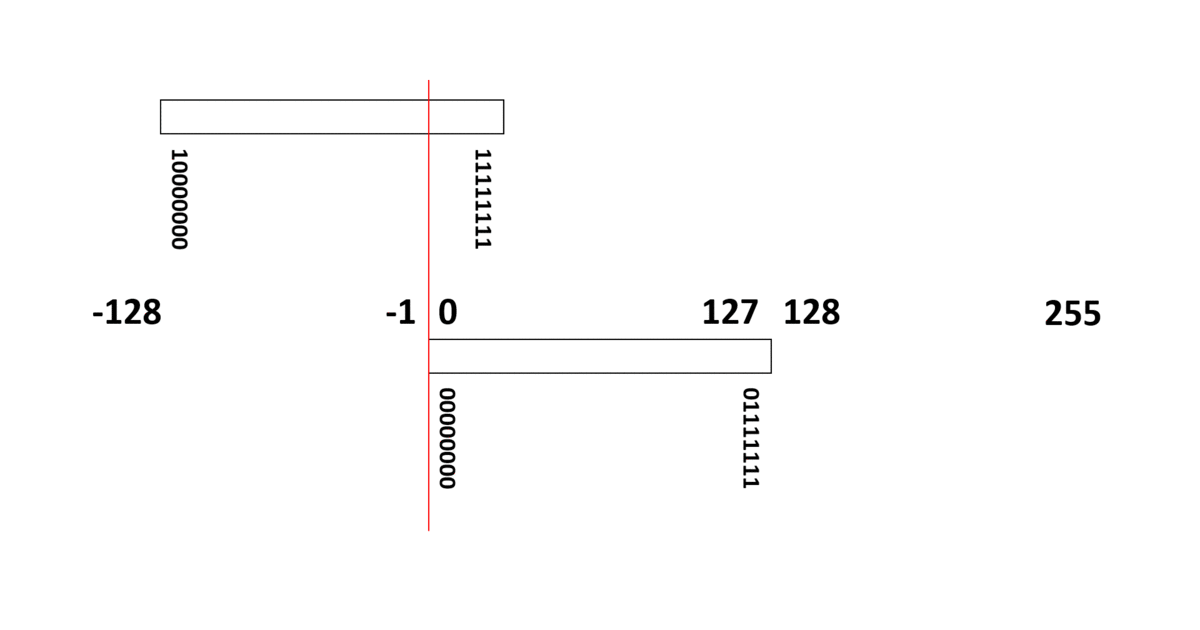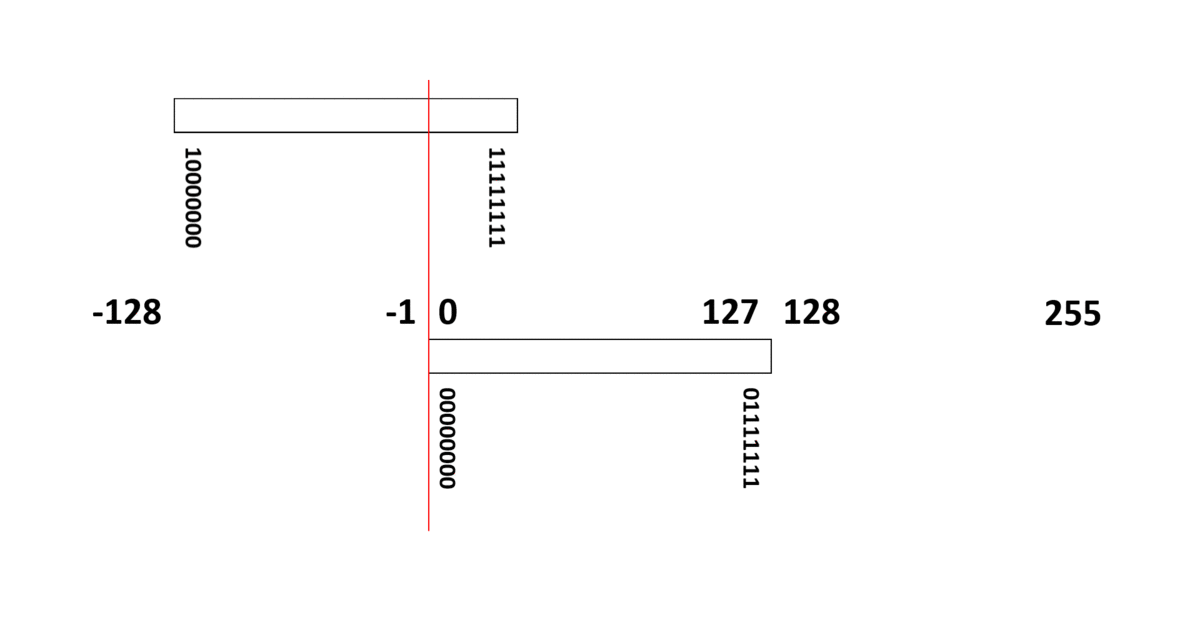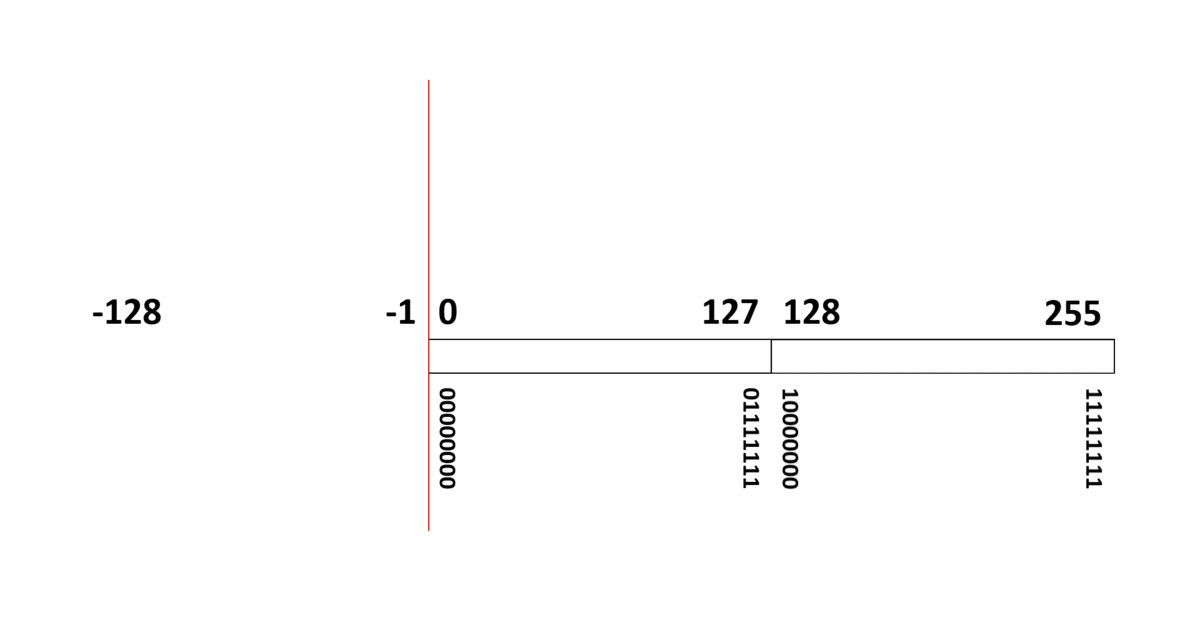
[10進数の -3 ] ⇒ [2進数の -11 ] ⇒ [負号無し2進数の 11111101 ]
負整数は、多くの場合、正整数と同じ扱いができる方式【2の補数(two’s complement)】が採用されています。
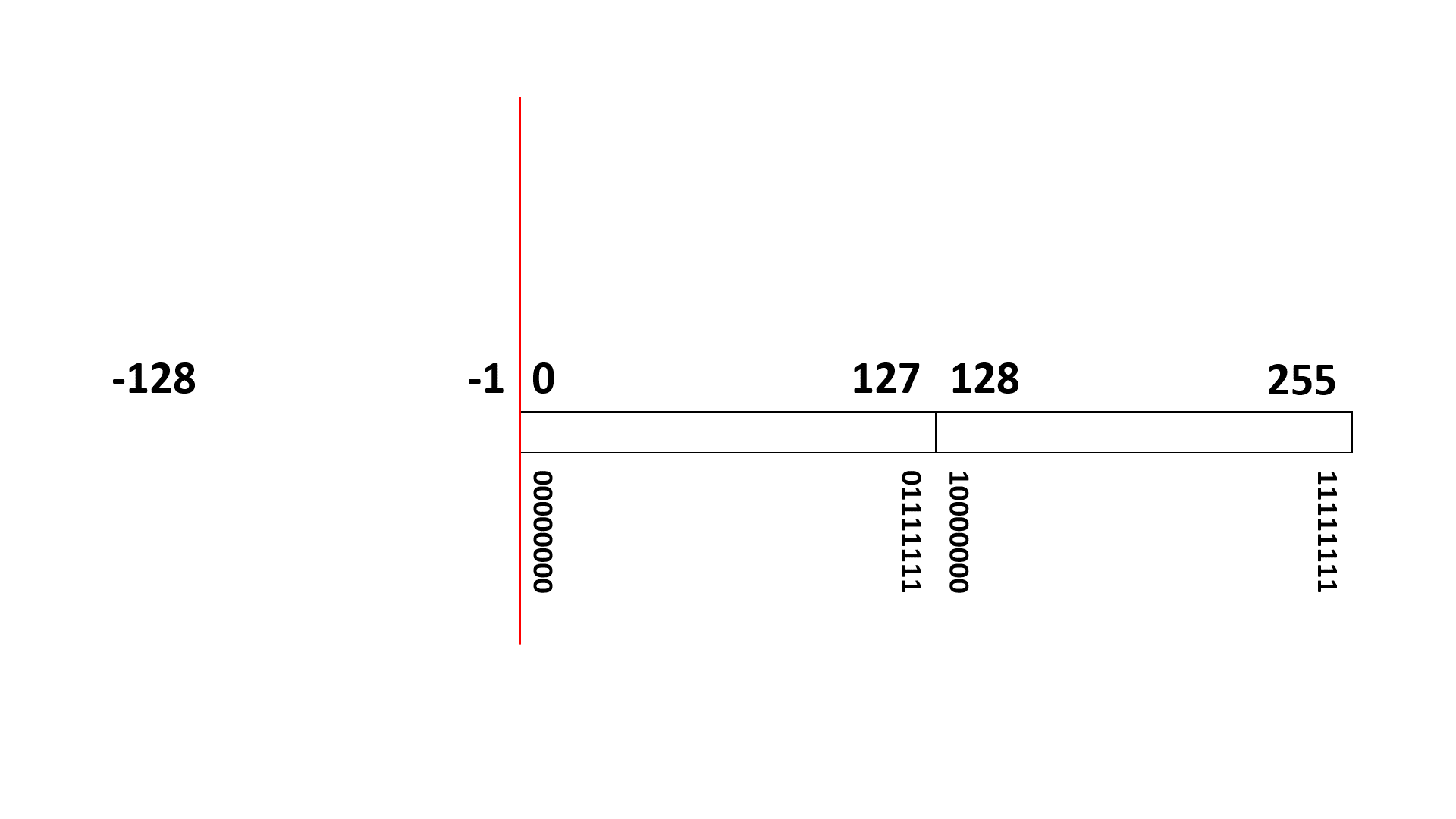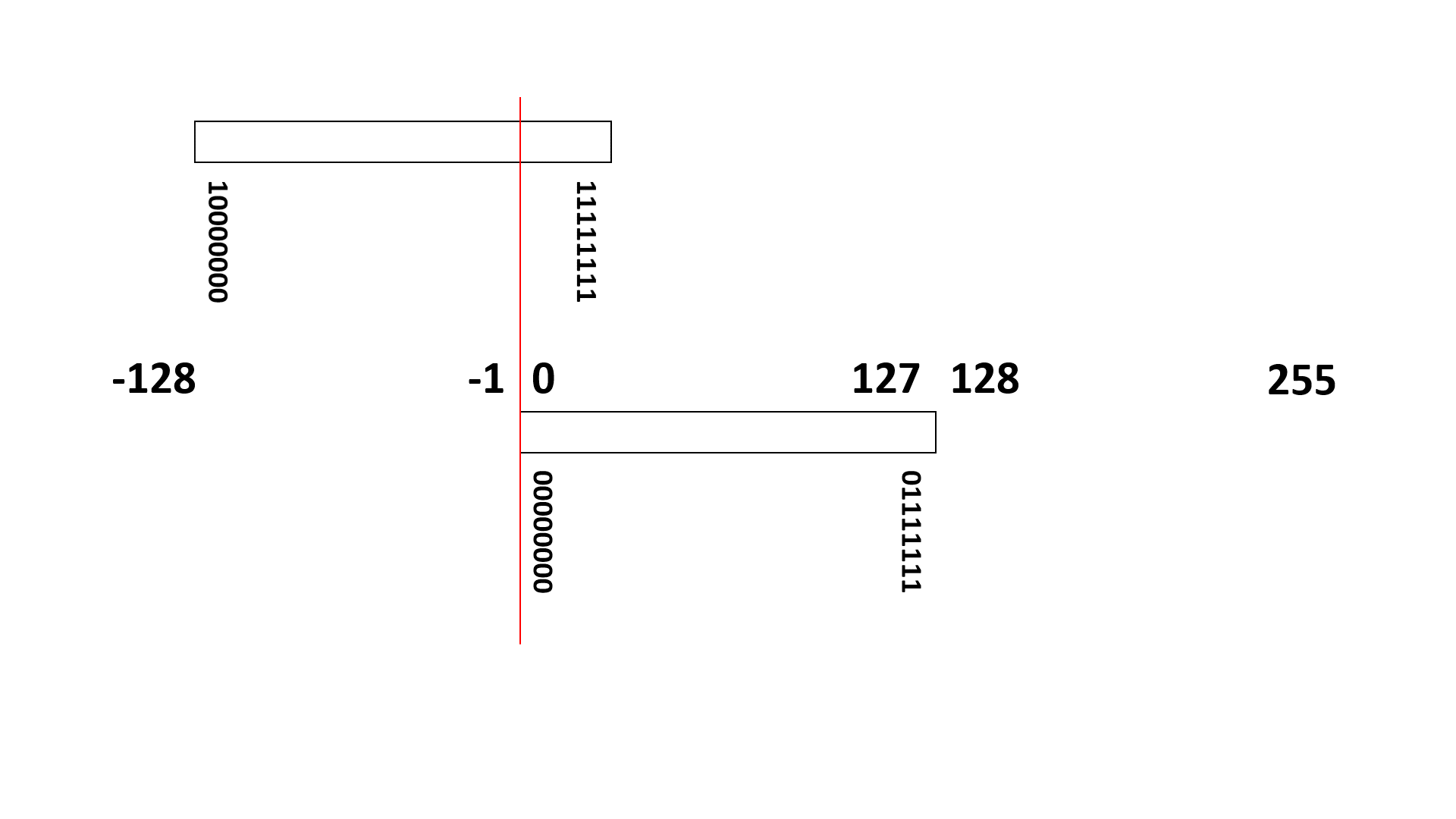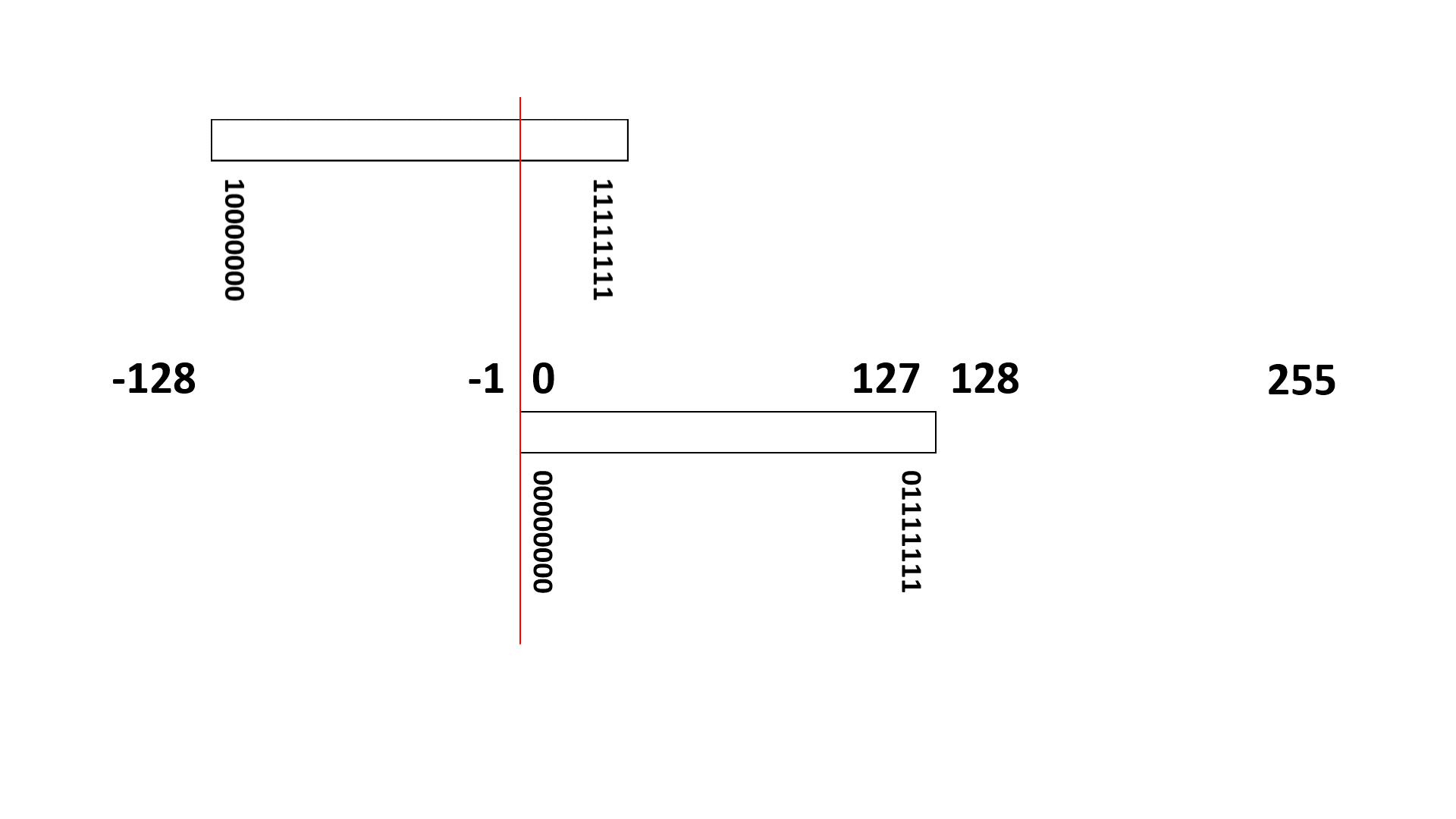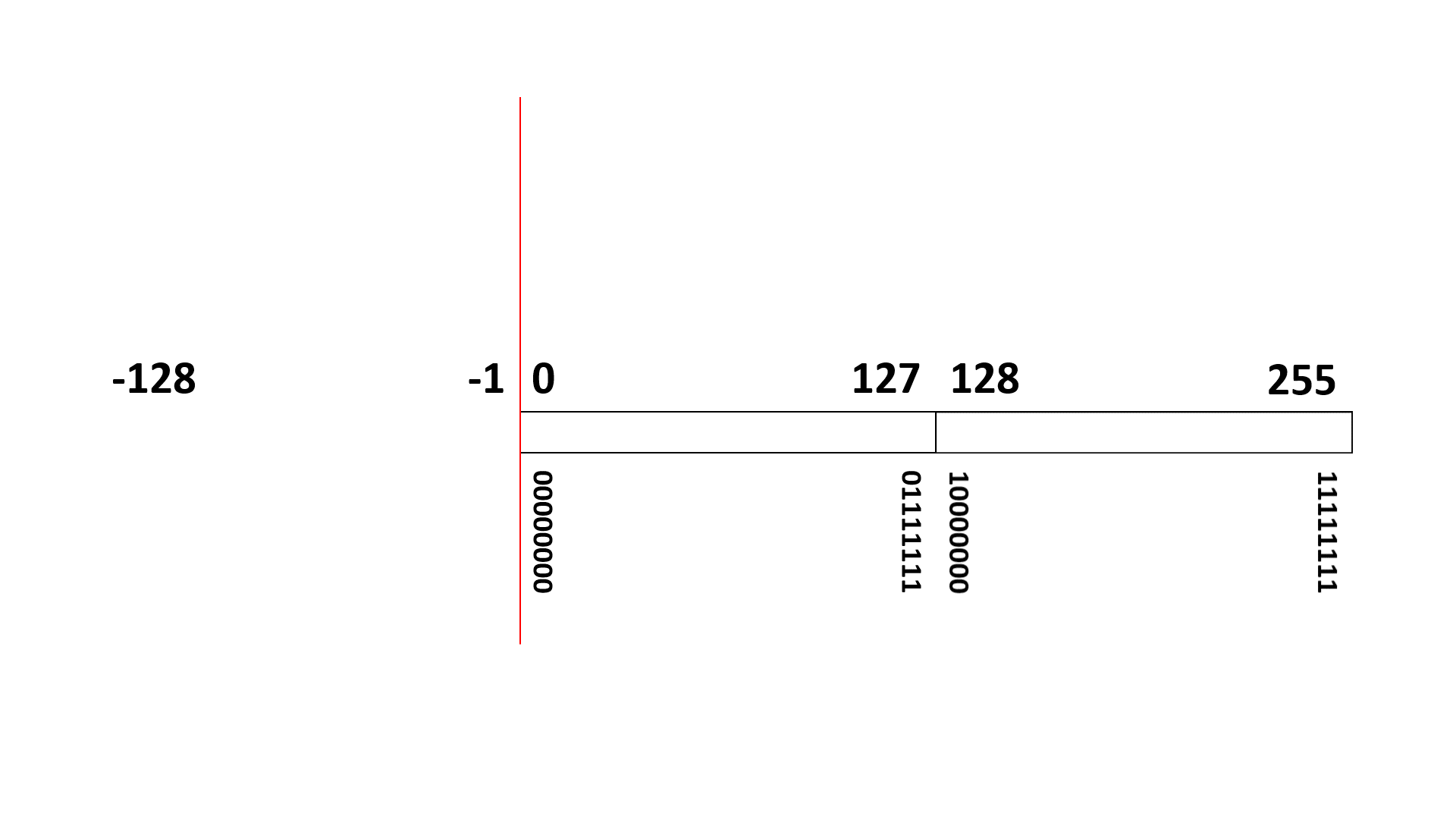
例えば8ビット表現の符号あり整数データ(00000000~11111111)は、10進数の 0 ~ 255 (正整数)を表すのではなく、(負整数) -128 ~ 127 (正整数)を表す整数データ(integer)として扱われます。
この方式は、11111111 に 00000001 を足すと、繰り上げビットの「桁あふれ」を無視すれば 00000000 となり、ループしてまた 0 に戻ることを利用しています。
つまり、
- (負整数) -128 ~ -1 は 10000000 ~ 11111111
- 0 は 00000000
- (正整数) 1 ~ 127 は 00000001 ~ 01111111
に、それぞれ変換されることになります。
負整数は、10進数だけで考えると「256を足した数値に変換される」と考えることもできます。実際、-128 は、256 足した 128 (10000000) に変換され、-1 は、256 足した 255 (11111111) に変換されます。
小数から変換する例
多くのコンピューターで採用されている変換方式【浮動小数点法(floating-point)】の場合、広範囲の数をそこそこの精度で扱えるようにしているため、小さな数でも、データの桁数はたくさん必要になります。
0.125 を 32ビット アーキテクチャ の 浮動小数点法 で表現した例
[十進数の 0.125 ] ⇒ [二進数の 0.001 ] ⇒ [小数点無し二進数の 00111110000000000000000000000000 ]
+/-|小数点シフト|小数部分
0: + / 1: – |元の数が1以上2未満になるまで2を掛けたり(2の+1乗)割ったり(2の-1乗)する|小数部分23桁表記
上の例では、
十進数表示なら、 0.125 = +1 × 1 / 8 = + 1.00000000000000000000000 × 2 の -3 乗
二進数表示なら、 0.001 = +1 × 1 / 1000 = + 1.00000000000000000000000 × 10 の -11 乗
累乗の負整数を負号無しに変換すると、
+ 1.00000000000000000000000 × 10 の (01111100 – 01111111)乗 【黒字部は固定値】
※ここでは累乗の負整数の変換に、2の補数方式ではなく、常に01111111を足すシフト方式が標準となっています。
– 00000011 + 01111111 = 01111100

データ型
そして、バイナリデータはプロセッサで処理され、また別のバイナリデータ (処理結果) になりますが、処理結果のバイナリデータは、基本的にまた変換前(バイナリデータ化前)と同じタイプのデータとして、復元できなければなりません。
この処理後の結果がまた戻るべき、バイナリデータ化前のデータのタイプを、データ型(data type)と言います。
データ型は、言語処理系によって、仕様が決まっており、メモリ上には最小限のデータを記録するだけで、データ型仕様に沿った様々な処理を、シンボルテーブルを含む言語処理系を通して、正しく扱えるようになっています。
データ型の例: 整数型、浮動小数点数型、文字列型、日付型、ブール型… etc.
日付型
日付(Date)の表記には通常、数値と文字が混ざっていますが、プログラミングでは、日付型は数値に近いデータ型として扱われます。一般的には、日付と時刻を合わせて日時として扱えたり、2つの日時の引き算から経過時間(Interval)を出せたり、ミリ秒単位(場合によってはさらに短時間単位)で扱えたりすることが共通します。
ブール型
プログラミングをする人以外にはイメージしづらいものとして、ブール型というデータ型もあります。ブール型は、TRUEまたはFALSEのどちらかの値しかとらないデータ型です。「〇か?×か?」という論理判定をブール代数という数学としてまとめた、ブール(Boole)さんの個人名から来ています。「ブールさんが考えたもの」という意味で、ブーリアン(Boolean)型と言われることもあります。
一般的には、1ビットのバイナリデータに変換され、〇ならTRUEで “1”、×ならFALSEで “0” となりますが、そうならない環境もありますので、注意が必要です。
なお、このように使われる1ビットのバイナリデータをフラグ(flag)と言います。
フラグと言うと専門用語らしく聞こえますが、フラッグ(旗)のことです。フラグにせよフラッグにせよ、AかBか2つの状態について、今はどちらなのかを知らせるのが flag の役目です。TRUEの状態になることを「フラグが立つ」と言います。FALSE状態のフラグには、様々な表現がありますが、イメージで言うと「フラグが寝る」がわかりやすいと思います。ドラマやアニメで、「真犯人フラグ」、「死亡フラグ」などとして使われるのも、同じ由来です。

バイナリ型
画像や音声のように文字化されていないデータを、高級プログラミング言語で扱う場合、通常、言語仕様として画像型や音声型のようなデータ型は作られません。
その代わりに、バイナリ(binary)型(あるいはBLOB型)と言われるようなユルいデータ型でひとくくりにして扱います。
BLOBは、Binary Large OBject の略ですが、英語の blob には元々「粒」のような意味があります。
バイナリ型とは、そのままバイナリデータとして扱えるようになっているデータのことで、バイナリデータはすべてバイナリ型です。
数値や文字列のように文字化されているデータをテキストデータと言い、画像や音声のように文字化されていないデータを非テキストデータと言います。
テキスト(text)とは、文字のことです。
非テキストデータは、通常、文字だけで書かれるソースコード上に表記することができません。そのため、他のデータ型と同じようにして扱うことはできないのです。
そこで、画像/音声は、画像/音声用のファイルフォーマットに従って記録された画像/音声データ、つまりファイルを、プログラムでの取り扱い単位とします。
したがって、バイナリ型のデータは、FILE型を通して間接的に扱うことが多くなっています。
そのファイルが、どんなファイルフォーマットに従って記録されているかは、通常、ファイル名に含まれる拡張子や、ファイルデータの冒頭(ファイルヘッダ)で判別できるようになっています。
プログラム間で扱われるデータ
プログラム間でのデータの扱いは、プログラム内でのデータの扱いとは、少し異なります。
小さなデータであれば、プロセス間通信などのプロトコルに従い、そのままデータ通信で扱われることもありますが、大きなデータでは、ファイル単位でデータを扱うことが多くなります。
プロトコルについて詳しく書くと、大きな脱線になってしまうので、ここでは詳しく触れません。
非テキストファイル
ファイル単位で扱う場合、非テキストデータであれば、上のバイナリ型のように扱われます。
テキストファイル
ファイル単位で扱うテキストデータでは、データ構造を持つかどうかで、さらに扱いが変わります。
データ構造を持たないテキストファイル
データ構造を持たない場合は、ファイル拡張子にtxtを付け、バイト単位でデータを扱えるようにもなるのが、バイナリ型との違いです。他はバイナリ型と変わりません。
大きなテキストデータは、BLOBに対峙して特に CLOB: Character Large OBject と言う場合もあります。
データ構造を持つテキストファイル
データ構造を持つテキストファイルには、いくつかよく使われるファイルフォーマットがあります。
ファイルフォーマットに沿って、データを利用したり、フォーマット変換をしたりできます。
プログラミングでもよく使われるテキストファイルフォーマットを以下に示します。
テキストファイルフォーマット
固定長データ
固定長データは、データの先頭からの位置で、意味付けがされるデータです。
「何バイト目から何バイト目までが●●」とプログラム間であらかじめ扱うデータ構造を合わせておきます。
各個別データのバイト長が固定なので、固定長データと言います。
逆に、固定長データ以外は、各個別データのバイト長が可変であるため、可変長データと言います。
固定長データの例
TOKYO13962194
OSAKA08821899
ただし、以下のことをプログラム間で合わせておく必要があります。
- 1~5バイトが、都道府県(prefecture)
- 6~9バイトが、人口(population)[万人]
- 10~13バイトが、面積(area)[km2]
固定長データの特徴
- 固定長データの長所
- 必要最小限のデータだけで、ファイルを作れる。
- 固定長データの短所
- 意味付けや個別データのバイトサイズに変更があると、プログラムへの影響大。
CSV(Comma Separated Values)
CSVは、日本語では、カンマ区切りデータと言われることが多く、Excel ファイルのような表形式のデータをプログラム間で扱うのに適しています。
CSVの例
prefecture,population,area
TOKYO,1396,2194
OSAKA,882,1899
CSVの特徴
- CSVの長所
- データの余計な重複が無く、可変長データとしては最小ファイルサイズにできる。
- CSVの短所
- ファイルを直接人間が開いて見た時に、わかりにくい。
XML(Extensible Markup Language)
XMLは、HTMLのようなマークアップ言語を、様々なデータ構造に対応できるよう拡張した言語です。XMLだけで書かれたテキストファイルは、XMLのファイルフォーマットになります。
XMLの例
<prefecture name=”TOKYO”>
<population>1396</population>
<area>2194</area>
</prefecture>
<prefecture name=”OSAKA”>
<population>882</population>
<area>1899</area>
</prefecture>
XMLの特徴
- XMLの長所
- ウェブ技術との相性が良い。拡張性が高い。
- XMLの短所
- 開始タグと終了タグの繰り返しが多く、データサイズが大きくなる。
JSON(JavaScript Object Notation)
JSONは元々、JavaScript でのオブジェクトリテラルに使われていた記述形式でした。
JSONは、使い勝手の良さから、CSS やその他の言語にも応用されるようになりました。
JSONの例
TOKYO{
population:1396,
area:2194
}
OSAKA{
population:882,
area:1899
}
JSONの特徴
- JSONの長所
- オブジェクト指向プログラミングとの相性が良い。
- JSONの短所
- 若干、ファイルサイズは大きくなる。
この記事のまとめ
コンピューター内で扱われる全てのデータは、2進数の数値、つまりバイナリデータです。
自然数以外の数値では、バイナリデータへの変換に少し工夫が必要で、通常、負数のバイナリデータ化には「2の補数」が使われ、小数のバイナリデータ化には「浮動小数点法」が使われます。
バイナリデータ化前のデータのタイプを、データ型(data type)と言います。
通常、画像データや音声データには、画像型や音声型のようなデータ型はなく、非テキストデータ型は、FILE型としてまとめられます。
プログラム間で扱われるテキストデータが、データ構造を持つ場合、適切なファイルフォーマットに合わせて、扱います。
次は、データストリーム に進みましょう。
この記事は、絵でわかる プログラムとは何か(5)~データ~ の一記事です。
コンピューターのしくみ全体を理解したい場合は、以下の2コースがお勧めです。
日本全国 オンラインレッスン にも対応しています。
知りたいことだけ単発で聞きたい場合は、 オンラインサポート をご利用ください。